22 minutes
Improving Geometry Serde Performance of Apache Sedona
Apache Sedona is an amazing project. It brings distributed geospatial processing capabilities to popular cluster computing systems such as Apache Spark and Apache Flink. In this post we’ll investigate on the performance characteristics of Spatial SQL on Apache Spark, and improve the performance of Spatial SQL by optimizing the geometry object serializer/deserializer in Apache Sedona.
Why Do We Care About the Performance of Geometry Serdes?
Spark SQL do not have native support for geometry columns and geometry
values. In order to bring geospatial support to Spark SQL, Apache Sedona
defined a UDT
(GeometryUDT)
for representing geospatial values in Spark SQL. UDT values are composed by
primitive Spark SQL values, Apache Sedona defines GeometryUDT as an array of
bytes, which contains the WKB representation of the geometry value.
WKB serialization/deserialization happens all the time when you run Spatial SQL
queries. Each time a spatial function was evaluated, the arguments of the
spatial function need to be deserialized. If the return value of that spatial
function is a geometry object, then that geometry object needs to be serialized
in order to be represented as a UDT value. Let’s take
ST_Transform
as an example, you can easily spot the serialization and deserialization code
in the eval method.
override def eval(input: InternalRow): Any = {
val geometry = inputExpressions(0).toGeometry(input)
val sourceCRSString = inputExpressions(1).asString(input)
val targetCRSString = inputExpressions(2).asString(input)
val lenient = inputExpressions(3).eval(input).asInstanceOf[Boolean]
(geometry,sourceCRSString,targetCRSString,lenient) match {
case (null,_,_,_) => null
case _ => Functions.transform(geometry, sourceCRSString, targetCRSString, lenient).toGenericArrayData
}
}
Now we know that serialization and deserialization of geometry objects are the common steps of evaluating spatial functions. If geometry serde takes fair amount of time when running Spatial SQL, it deserves careful optimization to reduce the performance overhead. Actually geometry serde is a big performance killer when running some commonly seen queries. Here is a Spatial SQL for selecting geometries within a given rectangular region:
SELECT COUNT(1) FROM ms_buildings
WHERE ST_Within(geom, ST_GeomFromText('POLYGON((-71.07418550113192 42.37012196853071,-71.0453463898038 42.37012196853071,-71.0453463898038 42.35096853399424,-71.07418550113192 42.35096853399424,-71.07418550113192 42.37012196853071))'))
It is a simple range query. Let’s profile one of the executor nodes when running this query using async-profiler and obtain a flamegraph. We can easily spot the performance bottleneck of this query: the purple highlighted horizontal bar in the following flamegraph indicates the cost of geometry object deserialization, which takes 64% of total running time. Spark SQL is not throwing most of our computation power to the geometry serde instead of doing useful work.
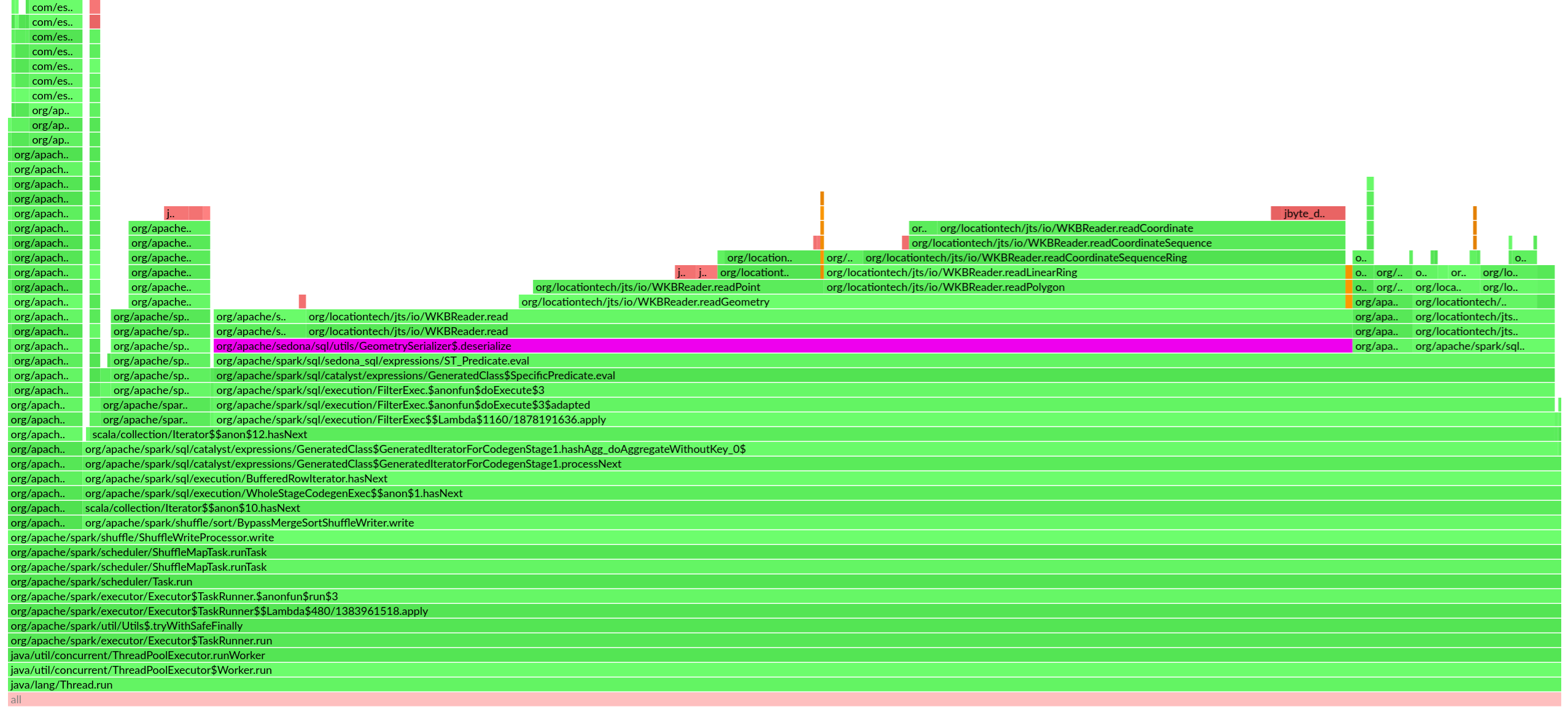
Now we know that geometry serde is the bottleneck of some particular kind of Spatial SQL query, it is time to optimize it.
You Have To Measure It In Order To Improve It.
Geometry serde is a small piece of CPU-intensive code, which seems to be fairly easy to benchmark. However, benchmarking things running on JVM is not an easy thing - you have to combat with the complicated, profile guided JIT compiler to obtain correct benchmark results. Fortunately, there’s a project named JMH for helping us getting rid of lots of traps and doing benchmarks correctly. We can setup our benchmark project based on JMH and start measuring.
There are 2 geometry serdes in Apache Sedona. We’ll benchmark both of them and pick up the better one as our starting point of rolling a faster serde. These 2 geometry serdes are:
GeometrySerializer: This is the geometry serde used byGeometryUDTand Spatial SQL. It is using WKB as serialization format.GeometrySerde: This is a serde based on Kryo for efficient serialization and deserialization of geometry objects in RDDs.
GeometrySerde does not only serialize geometry itself, it also serializes
user data attached to the geometry objects. So it is not completely fair to
compare GeometrySerde with GeometrySerializer. GeometrySerde uses
ShapeSerde
to serialize the pure geometry part. This is also the geometry serde for
reading Shapefiles.
To sum up, we have 3 serdes to benchmark: a WKB based GeometrySerializer, a
Kryo serde GeometrySerde and a shapefile compliant ShapeSerde. In order to
make things clear, we’ll refer to them as WkbSerde, KryoSerde and
ShapeSerde in the following texts.
Define the workload
We’ll benchmark the performance of serializing/deserializing 2D geometries with
X/Y coordinates since this is the most common use case. We’ll run these serdes
on various types of geometry objects (Point, LineString, Polygon,
MultiPolygon). For geometries with multiple coordinates, we run the tests on
geometry objects of various sizes. The segment parameter indicates the number
of nodes in the individual parts of the
geometry. BenchmarkedGeometries.java
is the code for preparing benchmarked geometries.
Run the Benchmark
Let’s run the benchmark with -f 3 -w 5 -r 5, which is a good balance between
running time and accuracy of measurements. This is the result obtained by
running the benchmark on an ECS instanace with 4 Intel(R) Xeon(R) Platinum
8269CY CPUs. Java version was OpenJDK 1.8.0_352. We’ve only included the result
of segment = 16 for saving screen space.
Benchmark (segments) Mode Cnt Score Error Units
BenchmarkWkbSerde.deserializeGeometryCollection 16 thrpt 15 148420.082 ± 8395.253 ops/s
BenchmarkKryoSerde.deserializeGeometryCollection 16 thrpt 15 179118.144 ± 2361.610 ops/s
BenchmarkWkbSerde.deserializeLineString 16 thrpt 15 1294007.710 ± 46441.569 ops/s
BenchmarkKryoSerde.deserializeLineString 16 thrpt 15 1419209.227 ± 43513.643 ops/s
BenchmarkShapeSerde.deserializeLineString 16 thrpt 15 2113479.014 ± 1003938.612 ops/s
BenchmarkWkbSerde.deserializeMultiPolygon 16 thrpt 15 340951.943 ± 12441.200 ops/s
BenchmarkKryoSerde.deserializeMultiPolygon 16 thrpt 15 468347.426 ± 13647.060 ops/s
BenchmarkShapeSerde.deserializeMultiPolygon 16 thrpt 15 928877.615 ± 23477.555 ops/s
BenchmarkWkbSerde.deserializePoint 16 thrpt 15 7693355.984 ± 193782.092 ops/s
BenchmarkKryoSerde.deserializePoint 16 thrpt 15 8174952.289 ± 318876.854 ops/s
BenchmarkShapeSerde.deserializePoint 16 thrpt 15 12494806.724 ± 634448.854 ops/s
BenchmarkWkbSerde.deserializePolygon 16 thrpt 15 1197937.023 ± 33104.487 ops/s
BenchmarkKryoSerde.deserializePolygon 16 thrpt 15 1234112.233 ± 74607.021 ops/s
BenchmarkShapeSerde.deserializePolygon 16 thrpt 15 2668153.092 ± 49593.190 ops/s
BenchmarkWkbSerde.deserializePolygonWithHoles 16 thrpt 15 392725.518 ± 25334.622 ops/s
BenchmarkKryoSerde.deserializePolygonWithHoles 16 thrpt 15 467200.201 ± 15385.118 ops/s
BenchmarkShapeSerde.deserializePolygonWithHoles 16 thrpt 15 939063.600 ± 27115.595 ops/s
BenchmarkWkbSerde.serializeGeometryCollection 16 thrpt 15 134069.692 ± 9140.104 ops/s
BenchmarkKryoSerde.serializeGeometryCollection 16 thrpt 15 244533.759 ± 5986.474 ops/s
BenchmarkWkbSerde.serializeLineString 16 thrpt 15 1226963.139 ± 48017.455 ops/s
BenchmarkKryoSerde.serializeLineString 16 thrpt 15 2068722.298 ± 118988.199 ops/s
BenchmarkShapeSerde.serializeLineString 16 thrpt 15 2460851.815 ± 41971.344 ops/s
BenchmarkWkbSerde.serializeMultiPolygon 16 thrpt 15 411487.421 ± 19040.631 ops/s
BenchmarkKryoSerde.serializeMultiPolygon 16 thrpt 15 693294.294 ± 12503.655 ops/s
BenchmarkShapeSerde.serializeMultiPolygon 16 thrpt 15 782453.061 ± 33955.116 ops/s
BenchmarkWkbSerde.serializePoint 16 thrpt 15 9222249.626 ± 306121.802 ops/s
BenchmarkKryoSerde.serializePoint 16 thrpt 15 10050255.878 ± 4309908.204 ops/s
BenchmarkShapeSerde.serializePoint 16 thrpt 15 29068624.264 ± 1483390.980 ops/s
BenchmarkWkbSerde.serializePolygon 16 thrpt 15 1164400.303 ± 42605.393 ops/s
BenchmarkKryoSerde.serializePolygon 16 thrpt 15 2035363.615 ± 71694.688 ops/s
BenchmarkShapeSerde.serializePolygon 16 thrpt 15 1896086.966 ± 516254.434 ops/s
BenchmarkWkbSerde.serializePolygonWithHoles 16 thrpt 15 442221.837 ± 10232.831 ops/s
BenchmarkKryoSerde.serializePolygonWithHoles 16 thrpt 15 660124.301 ± 19330.398 ops/s
BenchmarkShapeSerde.serializePolygonWithHoles 16 thrpt 15 765501.356 ± 89840.549 ops/s
Reading these Numbers
We can conclude that the performance of KryoSerde is slightly better than
WkbSerde in this particular environment, but significantly poorer than
ShapeSerde. It seems that ShapeSerde is good starting point for further
optimizing serde performance. However, we need to interpret these numbers with
caution to fully understand the benchmark results.
To understand the make up of computational costs when serializing and
deserializing geometry objects, we can profile it using a profiler. JMH has
builtin integration with async-profiler, so that we can instruct JMH to profile
it when running the benchmark. Let’s run the benchmark of serializing
MultiPolygons with segment = 16 as an example:
java -jar ./build/libs/play-with-geometry-serde-1.0-SNAPSHOT-jmh.jar "BenchmarkWkbSerde.serializeMultiPolygon" -f 1 -p "segments=16" -r 5s -w 5s -prof async:libPath=/path/to/libasyncProfiler.so\;output=flamegraph
First let’s find out why WKB is slow. Most of its time was spent on
WKBWriter.writeCoordinate. Its
implementation involves reordering eight bytes for floating point numbers
manually in
ByteOrderValues.putLong
and reallocations of the byte array in ByteArrayOutputStream.write. We may
wonder if the JIT compiler is smart enough to skip reordering when the byte
order of WKBWriter is native byte order, unfortunatally it is not the
case. We’ve also benchmarked WkbSerdeBigEndian and the result is about the
same with WkbSerde.

The next thing to see is the profiling result of KryoSerde. We can
immediately spot one big anomaly in the profiling result: why do we need to
create JTS points when serializing something? We should not create any geometry
objects in the serialization process.

The GeometryFactory.createPoint call took lots of time when serializing
geometry objects. We expect a huge performance improvement after pulling out
this sting. It is in
ShapeSerde.putPoints. We
can replace invocation of getPointN with getCoordinateN to avoid the
creation of point objects.
When it comes to deserialization, WkbSerde is slow in the same way with
serialization. KryoSerde is much slower than ShapeSerde, while it is mostly
based on ShapeSerde. We found that the extra performance cost introduced to
KryoSerde was in the
ShapeReader. Each
time the deserializer reads a floating point number, it fetches 8 bytes from
the Kryo input object, create a ByteBuffer object, then get a floating point
number out of it. There are too many small reads to the Kryo input stream and
we’ve wasted too much time creating ByteBuffer objects when the geometry to be
deserialized contains lots of coordinates.
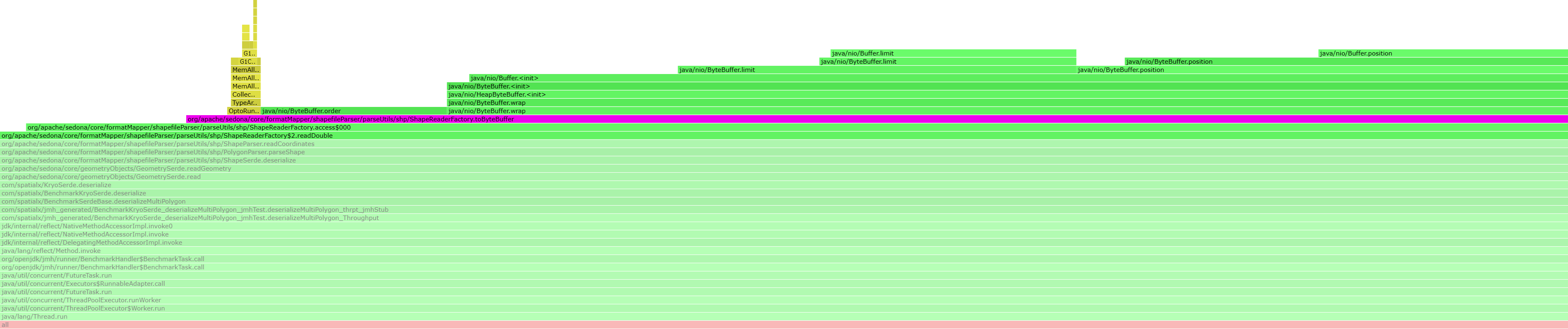
@Override
public double readDouble() {
return toByteBuffer(input, 8).getDouble();
}
private static ByteBuffer toByteBuffer(Input input, int numBytes) {
byte[] bytes = new byte[numBytes];
input.read(bytes);
return ByteBuffer.wrap(bytes).order(ByteOrder.LITTLE_ENDIAN);
}
A better way of reading coordinates from Kryo input is to read multiple coordinates at once. We can read a large chunk of byte array from Kryo input each time we want to read a CoordinateSequence of multiple coordinates.
@Override
public void readCoordinates(CoordinateSequence coordinateSequence, int numCoordinates) {
ByteBuffer bb = toByteBuffer(input, numCoordinates * 16);
for (int k = 0; k < numCoordinates; k++) {
coordinateSequence.setOrdinate(k, 0, bb.getDouble(16 * k));
coordinateSequence.setOrdinate(k, 1, bb.getDouble(16 * k + 8));
}
}
Improving the Performance of KryoSerde and ShapeSerde
We’ve fixed the performance problems mentioned above in our own fork
here. Benchmark
shows that our fix improved serde performance by roughly 30%, and the
performance gap between KryoSerde and ShapeSerde has also became smaller.
Benchmark (segments) Mode Cnt Score Error Units
BenchmarkKryoSerde.deserializeMultiPolygon 16 thrpt 15 445317.627 ± 8713.265 ops/s
BenchmarkKryoSerdeOptimized.deserializeMultiPolygon 16 thrpt 15 637855.796 ± 22901.547 ops/s
BenchmarkShapeSerdeOptimized.deserializeMultiPolygon 16 thrpt 15 583509.084 ± 240406.288 ops/s
BenchmarkKryoSerde.serializeMultiPolygon 16 thrpt 15 678090.693 ± 12838.073 ops/s
BenchmarkKryoSerdeOptimized.serializeMultiPolygon 16 thrpt 15 827620.426 ± 180365.455 ops/s
BenchmarkShapeSerdeOptimized.serializeMultiPolygon 16 thrpt 15 1296729.904 ± 16064.890 ops/s
How Can We Do Better?
Til now, the obvious performance problems in ShapeSerde have already been
resolved. We need to dig deeper to get better performance. We can hardly find
anything to improve by looking at ShapeSerde's code, it is already a very
compact, hassle free implementation of geometry serde using
java.nio.ByteBuffer. The profiling result shows that the next thing to
improve might be ByteBuffer.getDouble (though profiling result was not that
accurate when everything was heavily inlined by the C2 optimizer), what can we
do to improve the performance of reading 64-bit floating point number from a
byte buffer?

We can inspect the assembly code generated by the C2 compiler, it shows that
the HeapByteBuffer.getDouble method is fetching floating point numbers from
memory in a very dumb way: it reads 8 bytes one after another, then assembly
them together in little-endian byte oder to form a double.
0x00007fa741245edb: movzbl 0x18(%r13,%r10,1),%r8d ;*land
; - java.nio.Bits::makeLong@74 (line 307)
; - java.nio.Bits::getLongL@56 (line 318)
; - java.nio.Bits::getDoubleL@2 (line 497)
; - java.nio.Bits::getDouble@14 (line 513)
; - java.nio.HeapByteBuffer::getDouble@15 (line 531)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@29 (line 58)
0x00007fa741245ee1: movzbl 0x19(%r13,%r10,1),%r11d ;*land
; - java.nio.Bits::makeLong@63 (line 307)
; - java.nio.Bits::getLongL@56 (line 318)
; - java.nio.Bits::getDoubleL@2 (line 497)
; - java.nio.Bits::getDouble@14 (line 513)
; - java.nio.HeapByteBuffer::getDouble@15 (line 531)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@29 (line 58)
0x00007fa741245ee7: movzbl 0x1a(%r13,%r10,1),%ecx ;*land
; - java.nio.Bits::makeLong@52 (line 307)
; - java.nio.Bits::getLongL@56 (line 318)
; - java.nio.Bits::getDoubleL@2 (line 497)
; - java.nio.Bits::getDouble@14 (line 513)
; - java.nio.HeapByteBuffer::getDouble@15 (line 531)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@29 (line 58)
0x00007fa741245eed: movzbl 0x1c(%r13,%r10,1),%r9d ;*land
; - java.nio.Bits::makeLong@30 (line 307)
; - java.nio.Bits::getLongL@56 (line 318)
; - java.nio.Bits::getDoubleL@2 (line 497)
; - java.nio.Bits::getDouble@14 (line 513)
; - java.nio.HeapByteBuffer::getDouble@15 (line 531)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@29 (line 58)
0x00007fa741245ef3: movzbl 0x1d(%r13,%r10,1),%edx ;*land
; - java.nio.Bits::makeLong@20 (line 307)
; - java.nio.Bits::getLongL@56 (line 318)
; - java.nio.Bits::getDoubleL@2 (line 497)
; - java.nio.Bits::getDouble@14 (line 513)
; - java.nio.HeapByteBuffer::getDouble@15 (line 531)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@29 (line 58)
0x00007fa741245ef9: movzbl 0x1e(%r13,%r10,1),%ebx ;*land
; - java.nio.Bits::makeLong@10 (line 307)
; - java.nio.Bits::getLongL@56 (line 318)
; - java.nio.Bits::getDoubleL@2 (line 497)
; - java.nio.Bits::getDouble@14 (line 513)
; - java.nio.HeapByteBuffer::getDouble@15 (line 531)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@29 (line 58)
0x00007fa741245eff: movsbl 0x1f(%r13,%r10,1),%eax ;*baload
; - java.nio.HeapByteBuffer::_get@5 (line 255)
; - java.nio.Bits::getLongL@5 (line 318)
; - java.nio.Bits::getDoubleL@2 (line 497)
; - java.nio.Bits::getDouble@14 (line 513)
; - java.nio.HeapByteBuffer::getDouble@15 (line 531)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@29 (line 58)
0x00007fa741245f05: movzbl 0x1b(%r13,%r10,1),%r10d ;*land
; - java.nio.Bits::makeLong@41 (line 307)
; - java.nio.Bits::getLongL@56 (line 318)
; - java.nio.Bits::getDoubleL@2 (line 497)
; - java.nio.Bits::getDouble@14 (line 513)
; - java.nio.HeapByteBuffer::getDouble@15 (line 531)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@29 (line 58)
0x00007fa741245f0b: movslq %r8d,%r8
0x00007fa741245f0e: movslq %r10d,%r10
0x00007fa741245f11: add $0x10,%edi
0x00007fa741245f14: vmovq %xmm3,%rsi
0x00007fa741245f19: mov %edi,0x18(%rsi) ;*putfield position
; - java.nio.Buffer::nextGetIndex@27 (line 511)
; - java.nio.HeapByteBuffer::getDouble@5 (line 531)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@29 (line 58)
0x00007fa741245f1c: shl $0x18,%r10
0x00007fa741245f20: movslq %eax,%rdi
0x00007fa741245f23: movslq %ebx,%rbx
0x00007fa741245f26: shl $0x38,%rdi
0x00007fa741245f2a: shl $0x30,%rbx
0x00007fa741245f2e: or %rbx,%rdi
0x00007fa741245f31: movslq %edx,%rbx
0x00007fa741245f34: movslq %r9d,%r9
0x00007fa741245f37: shl $0x28,%rbx
0x00007fa741245f3b: or %rbx,%rdi
0x00007fa741245f3e: shl $0x20,%r9
0x00007fa741245f42: or %r9,%rdi
0x00007fa741245f45: or %rdi,%r10
0x00007fa741245f48: movslq %ecx,%r9
0x00007fa741245f4b: movslq %r11d,%r11
0x00007fa741245f4e: shl $0x10,%r9
0x00007fa741245f52: or %r9,%r10
0x00007fa741245f55: shl $0x8,%r11
0x00007fa741245f59: or %r11,%r10
0x00007fa741245f5c: or %r8,%r10
0x00007fa741245f5f: vmovq %r10,%xmm6
0x00007fa741245f64: vmovd %xmm8,%r10d
0x00007fa741245f69: vmovsd %xmm6,0x18(%r12,%r10,8) ;*putfield y
; - org.locationtech.jts.geom.impl.CoordinateArraySequence::setOrdinate@48 (line 301)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@32 (line 58)
The assembly shows that HeapByteBuffer.getDouble was inlined into
readCoordinates, and some instruction fragments matches well with the source
code of
java.nio.Bits.getDouble,
and there seems to be no special optimizations for this method.
static private long makeLong(byte b7, byte b6, byte b5, byte b4,
byte b3, byte b2, byte b1, byte b0)
{
return ((((long)b7 ) << 56) |
(((long)b6 & 0xff) << 48) |
(((long)b5 & 0xff) << 40) |
(((long)b4 & 0xff) << 32) |
(((long)b3 & 0xff) << 24) |
(((long)b2 & 0xff) << 16) |
(((long)b1 & 0xff) << 8) |
(((long)b0 & 0xff) ));
}
static double getDoubleL(ByteBuffer bb, int bi) {
return Double.longBitsToDouble(getLongL(bb, bi));
}
static double getDouble(ByteBuffer bb, int bi, boolean bigEndian) {
return bigEndian ? getDoubleB(bb, bi) : getDoubleL(bb, bi);
}
The assembly and source code above were obtained from JDK 8. We’ve also found
that the implementation of java.nio.HeapByteBuffer has changed in JDK 11,
HeapByteBuffer.getDouble
calls UNSAFE.getLongUnaligned to read a 64-bit long instead of calling
java.nio.Bits. Unsafe.getLongUnaligned is a HotSpot intrinsic candidate,
which means that some specialized optimizations may kick in to generate better
machine code for this method. We can get the following assembly code of
readCoordinates when running the same benchmark using OpenJDK 11:
0x00007fc5482f5335: movsxd %ebp,%r10
0x00007fc5482f5338: mov (%rsi,%r10),%r10
0x00007fc5482f533c: vmovq %r10,%xmm3 ;*invokestatic longBitsToDouble {reexecute=0 rethrow=0 return_oop=0}
; - java.nio.HeapByteBuffer::getDouble@27 (line 563)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@14 (line 57)
0x00007fc5482f5341: mov %ebp,%r10d
0x00007fc5482f5344: add $0x8,%r10d ;*iadd {reexecute=0 rethrow=0 return_oop=0}
; - java.nio.Buffer::nextGetIndex@26 (line 652)
; - java.nio.HeapByteBuffer::getDouble@11 (line 562)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@14 (line 57)
0x00007fc5482f5348: mov %r10d,0x18(%r9) ;*putfield position {reexecute=0 rethrow=0 return_oop=0}
; - java.nio.Buffer::nextGetIndex@27 (line 652)
; - java.nio.HeapByteBuffer::getDouble@11 (line 562)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@14 (line 57)
0x00007fc5482f534c: vmovsd %xmm3,0x10(%r12,%rdx,8) ;*putfield x {reexecute=0 rethrow=0 return_oop=0}
; - org.locationtech.jts.geom.impl.CoordinateArraySequence::setOrdinate@35 (line 298)
; - org.apache.sedona.core.formatMapper.shapefileParser.parseUtils.shp.ShapeReaderFactory$1::readCoordinates@17 (line 57)
; implicit exception: dispatches to 0x00007fc5482f5445
Now HeapByteBuffer.getDouble is a compiled as a mov and a movq
instruction, instead of 8 movzbls plus a bunch of cryptic bit operation
instructions. This is much closer to what want. The benchmark shows that
ShapeSerdeOptimized runs 2x faster on OpenJDK 11 than on OpenJDK 8, the more
efficient HeapByteBuffer.getDouble may have contributed a lot to the overall
performance improvements.
OpenJDK 8:
Benchmark (segments) Mode Cnt Score Error Units
BenchmarkShapeSerdeOptimized.deserializeMultiPolygon 16 thrpt 5 277629.569 ± 14558.878 ops/s
BenchmarkShapeSerdeOptimized.serializeMultiPolygon 16 thrpt 5 1274689.454 ± 28635.789 ops/s
OpenJDK 11:
Benchmark (segments) Mode Cnt Score Error Units
BenchmarkShapeSerdeOptimized.deserializeMultiPolygon 16 thrpt 5 1290509.273 ± 94472.337 ops/s
BenchmarkShapeSerdeOptimized.serializeMultiPolygon 16 thrpt 5 3633453.311 ± 109287.692 ops/s
We don’t want our users to get good performance only when using JDK 11+ since
JDK 8 is still widely used. However, we have found a way to deal with this
problem: we can use Unsafe to get close-to-optimal performance even when using
JDK 8. The only concern is that Unsafe is being deprecated, then we can
implement 2 versions of our buffer accessor: one is based on Unsafe, the other
is based on java.nio.HeapByteBuffer. If Unsafe was completely removed from
future version of JDK, the performance of HeapByteBuffer would still be good
enough to power a fast serde.
After eliminating the performance issue of getDouble, the cost of isCCW
became significant. ShapeSerde comforms with the Shapefile standard and uses
orientations (CCW, CW order) of linear rings in polygons to resolve which rings
belong to the same polygon when deserializing MultiPolygons. It seems to be
beneficial to come up with a new serde which eliminates the need for isCCW.

There are other problems with ShapeSerde:
- Each serialized buffer has 32 unused bytes: they were 4 floating point
values left for storing the bounding box of the geometry. We can not remove
them from
ShapeSerdesince it has to conform with the Shapefile format. - Floating point numbers were not aligned to 8-byte boundaries. It brings some performance penalty when loading and storing coordinate values.
- Only 2D geometries were supported. It does not support SRID and Z/M dimensions.
These problems cannot be easily resolved if we keep working on ShapeSerde, it
is time to come up with a better serialization format.
Design a Better Geometry Serialization Format
Now we’ve got everything we need to know to design a fast geometry serde. We know that serialized geometries are not expected to be persisted and results of serialization are transient, there’s no need to take forward compatibility and extensibility issues into consideration. The only thing we need to take care of is speed. Our design principles are:
- We don’t need to take byte order into consideration. The serialized object won’t be persisted and deserialized by a machine with different endianness. We can also safely assume that the workers in a Spark cluster are of the same endianness since Spark itself already assumed so.
- Floating point numbers and integers should be properly aligned. We don’t want to handle the unaligned load/store cases, and through proper design of our serialization format, the padding introduced by alignment could be negligible.
- It may be better to store the structure of MultiPolygon explicitly instead of relying on CCW/CW order of rings.
- It should support SRID and 3D/4D geometries (Z/M dimensions).
With these principles in mind, let’s design our geometry serialization format.
The Overall Design
Our proposed serialization format is similar to WKB, the major difference is that the coordinate values were always aligned to 8-byte boundaries. The serialized buffer consists of 3 parts:
- The header, which is the first 8 bytes of the serialized buffer containing the geometry type, coordinate dimensions, SRID (optional), and the total number of coordinates.
- The coordinate data, which contains the coordinates of all points in the geometry.
- The structure data is a series of 32-bit integers, which contains the structure of the geometry. For example, the structure of a MultiPolygon is the number of polygons, the number of rings in each polygon, and the number of coordinates in each ring.
By storing coordinate data and structure data separately, we can make sure that the coordinate data and structure data are always aligned to word boundaries.
[ header ] [ coordinate data ] [ structure data ]
|< 8 bytes >| |< variable length >| |< variable length>|
The subsections below will explain the details of the format.
Header
The header has a fixed size of 8 bytes. It contains one preamble byte, 3 bytes for SRID, and 4 bytes for the total number of coordinates.
[ preamble ] [srid_hi] [srid_mid] [srid_lo] [ numCoordinates ]
|< 1 byte >| |<- 3 bytes ->| |<- 4 bytes ->|
The preamble byte is used to store the geometry type, coordinate dimensions, and SRID flag. The first 4 bits are used to store the geometry type, the next 3 bits are used to store the coordinate dimensions, and the last bit is used to store the SRID flag.
[ geometryType ] [ coordinateType ] [ SRID flag ]
|<- 4 bits ->| |<- 3 bits ->| |<- 1 bit ->|
The geometry type value is defined in the same way as 2D geometries in WKB:
| Geometry Type | Value |
|---|---|
| Point | 1 |
| LineString | 2 |
| Polygon | 3 |
| MultiPoint | 4 |
| MultiLineString | 5 |
| MultiPolyogn | 6 |
| GeometryCollection | 7 |
The coordinate type value is defined as follows:
| Coordinate Type | Value |
|---|---|
| XY | 1 |
| XYZ | 2 |
| XYM | 3 |
| XYZM | 4 |
We use 3 bytes (24 bits) to store the SRID of the geometry. The SRID flag in the preamble byte is used to indicate whether the SRID is specified. If the SRID flag is 0, the SRID is not specified and the 3 bytes for SRID are all 0. If the SRID flag is 1, the SRID is specified and the 3 bytes for SRID are used to store the SRID in big-endian order. We know that SRID is a 32-bit integer in JTS, thus serializing SRID as 3 bytes rules out some geometries with large SRID values. We don’t think this is a problem since SRID larger than 16777215 is rarely used, and the GSERIALIZED format defined by PostGIS also uses 3 bytes (21 bits actually) to store SRIDs and we didn’t see many complaints about that.
The total number of coordinates is stored in a 32-bit integer in native byte order. It is used to calculate the size of the coordinate data.
The header could be represented by ANSI C struct as follows:
struct Preamable {
int geometryType : 4;
int coordinateType: 3;
boolean sridFlag: 1;
};
struct Header {
Preamable preamble;
unsigned char srid[3];
int numCoordinates;
};
Coordinate Data
The coordinate data is a contiguous array of ordinate values. The size of the coordinate data is calculated by multiplying the total number of coordinates by the size of each coordinate. The size of each coordinate is determined by the coordinate type.
Each ordinate was stored as an 8-byte floating point number in native byte order. Ordinates of the same coordinate were stored consecutively. For example, the coordinate data of a 2D point is 16 bytes long, and the coordinate data of a 3D point is 24 bytes long.
Structure Data
The structure data is a contiguous array of 32-bit integers. The content of structure data is defined differently for each type of geometry. We’ll show you the structure data of each geometry type in the next section.
Format of Each Geometry Type
Point
An empty point can be serialized as 8 bytes, which is the size of the header. The numCoordinates field in the header should be 0.
A non-empty point should have a header with numCoordinates value set to 1, followed by the coordinate data.
The structure data is empty in both cases.
LineString
A LineString is serialized as a header followed by the coordinate data. The numCoordinates field in the header should be set to the number of points in the LineString. The structure data is always empty.
Polygon
A Polygon is serialized as a header followed by the coordinate data. The numCoordinates field in the header should be set to the number of points in the Polygon (total number of points in exterior ring and inner rings).
The structure data contains the number of rings in the Polygon, and the number of points in each ring. For example, a polygon with an exterior ring with 5 points and an interior ring with 3 points will have the following structure data:
[ 2 ] [ 5 ] [ 3 ]
^ ^ ^
| | |
| | +-- number of points in inner ring 1
| +-- number of points in the exterior ring
+-- number of rings
MultiPoint
A MultiPoint is serialized as a header followed by the coordinate data. The numCoordinates field in the header should be set to the total number of points in the MultiPoint. The structure data is always empty.
Empty points in MultiPoint are serialized with all ordinates set to NaN.
MultiLineString
A MultiLineString is serialized as a header followed by the coordinate data. The numCoordinates field in the header should be set to the total number of points in the MultiLineString. The structure data contains the number of LineStrings in the MultiLineString, and the number of points in each LineString.
MultiPolygon
A MultiPolygon is serialized as a header followed by the coordinate data. The numCoordinates field in the header should be set to the total number of points in the MultiPolygon.
The structure data contains the number of Polygons in the MultiPolygon, the number of rings in each Polygon, and the number of points in each ring. For example, a MultiPolygon with a Polygon with an exterior ring with 5 points and an interior ring with 3 points, and a Polygon with an exterior ring with 4 points will have the following structure data:
[ 2 ] [ 2 ] [ 5 ] [ 3 ] [ 1 ] [ 4 ]
^ ^ ^ ^ ^ ^
| | | | | |
| | | | | +-- number of points in the exterior ring of polygon 2
| | | | +-- number of rings in polygon 2
| | | +-- number of points in inner ring 1 of polygon 1
| | +-- number of points in the exterior ring of polygon 1
| +-- number of rings in polygon 1
+-- number of polygons
GeometryCollection
A GeometryCollection is serialized as a header followed by serialized geometry data of each geometry in the collection. The numCoordinates field in the header should be set to the total number of geometries in the GeometryCollection.
The serialized geometry data of each geometry were aligned to 8-byte boundaries. Paddings should be added when necessary and the values of padding bytes were unspecified.
Benchmark Results
We’ve implemented the proposed format in com.spatialx.fastserde.GeometrySerializer. This geometry serde has 2 buffer accessors: one was backed by Unsafe and the other was backed by ByteBuffer. We’ve benchmarked the proposed serde with both buffer accessors and obtained the following results. We can see that the performance of the Unsafe variant of our proposed serde is way faster than other serdes. The performance of the ByteBuffer variant is on par with ShapeSerdeOptimized and significantly slower than the Unsafe variant. This is because the performance of ByteBuffer is quite poor compared to Unsafe on JDK 8.
In practice, we use the Unsafe variant of our proposed serde in production environment, and fallback to the ByteBuffer variant when sun.misc.Unsafe is not available.
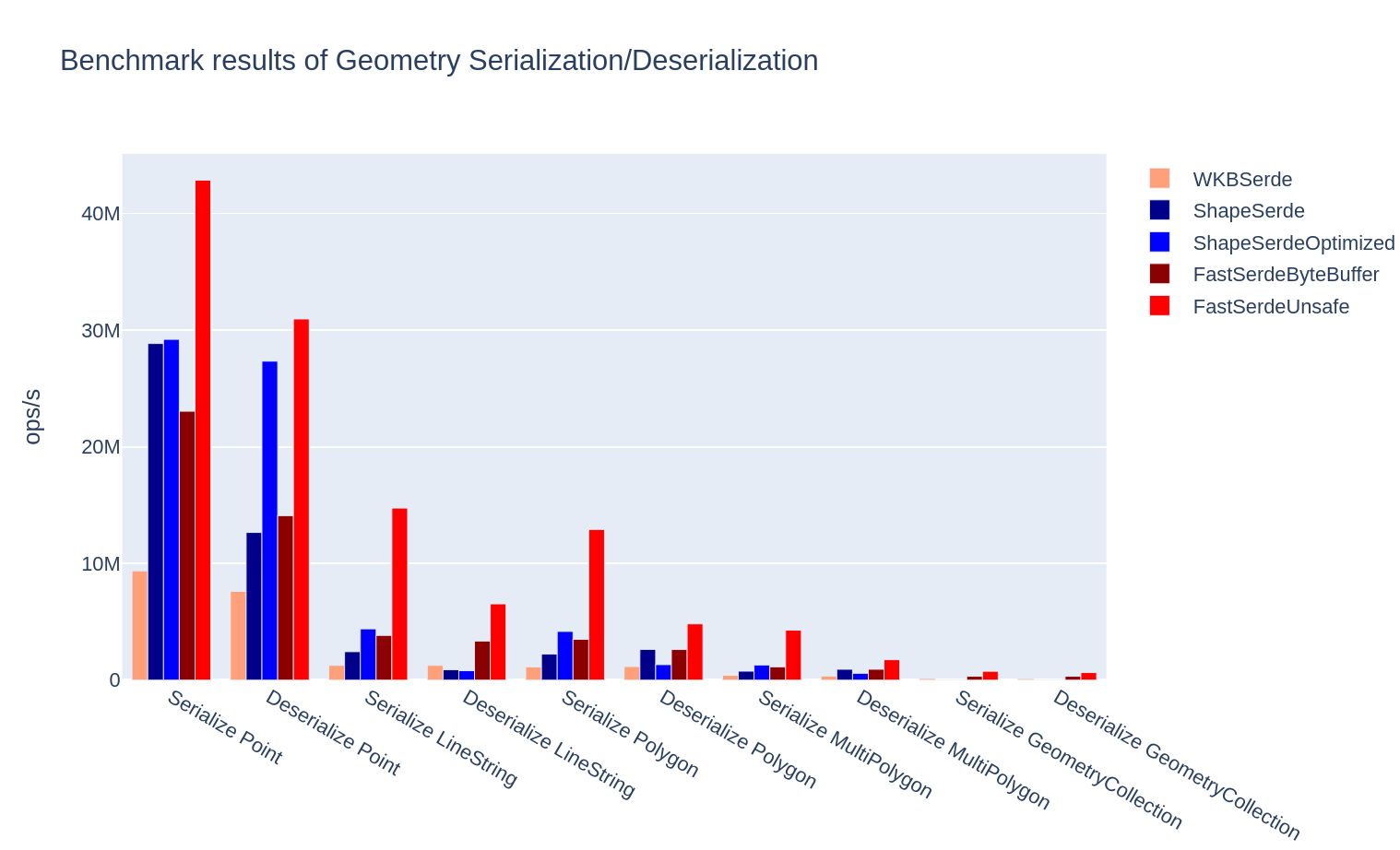
We’ve only plotted the results of serializing/deserializing geometries with 16 segments. Detailed benchmark results can be found in the README of the benchmark project.
Overall Performance Improvement of Spatial SQL
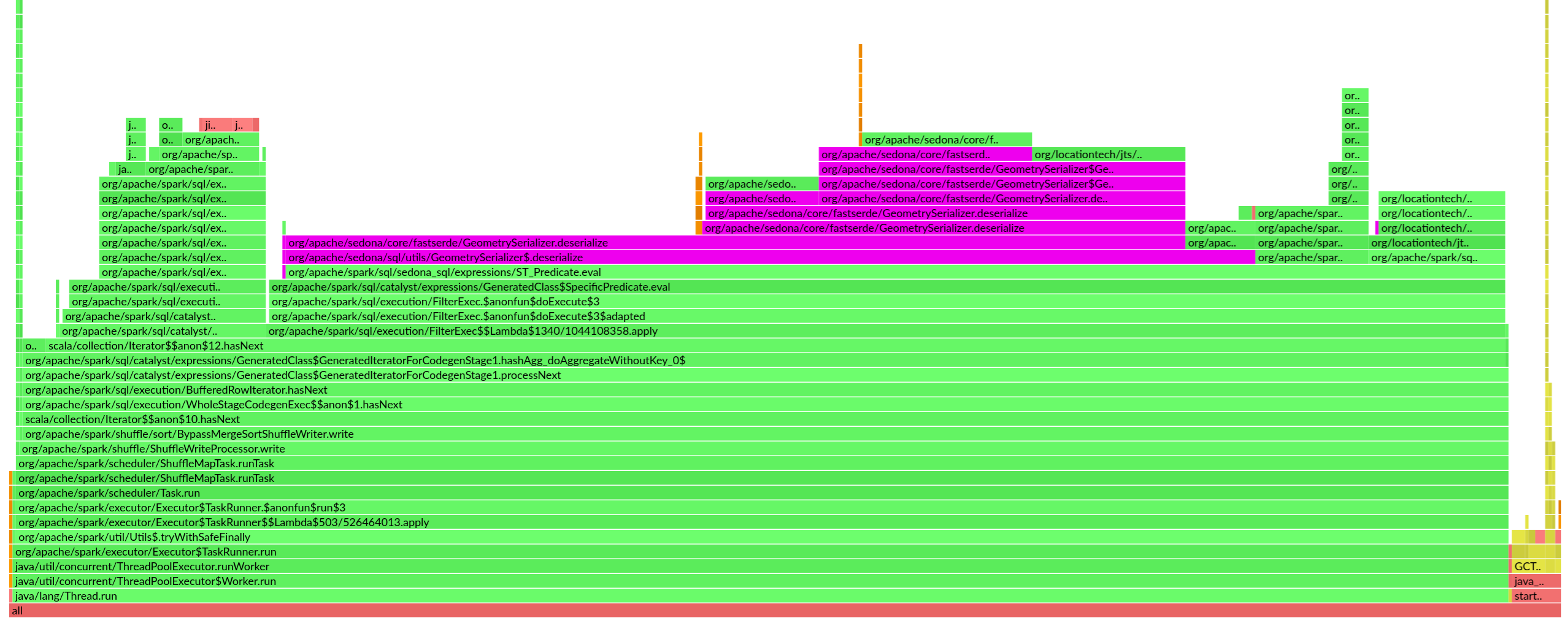
We’ve implemented the proposed geometry serde in our own fork of Apache Sedona and observed 2x speed up of range queries.
| Spatial SQL | Geometry Type | Record Count | Result Count | Cost with existing serde | Cost with proposed serde |
|---|---|---|---|---|---|
SELECT COUNT(1) FROM traj_points WHERE ST_Within(geom, ...) |
Point | 62,909,383 | 856,881 | 20 s | 9 s |
SELECT COUNT(1) FROM ms_buildings WHERE ST_Within(geom, ...) |
Polygon | 18,553,228 | 460 | 8 s | 4 s |
Although we’ve achieved remarkable speed up by optimizing the geometry serde, there is still significant proportion of time spent on geometry serde when running range queries. We can perform further optimization by avoiding repeatedly serializing/deserializing the constant geometry in the WHERE clause. This optimization is out of the scope of this proposal and we will work on it in the future.
Future Work
There’re a lot of things to do to integrate it into Apache Sedona. We’ll implement a python version of proposed serde as a C extension, and also implement a pure python version using struct package as a fallback.